

In this article I’m sharing an example of how to use NGINX Amplify as a visualization and reporting tool for benchmarking application performance. The primary focus is measuring the effect on performance of keepalive connections.
As you’ll see at the conclusion, we found that we can double performance in a realistic testing scenario by using TCP keepalive connections. Using the NGINX upstream keepalive mechanism reduces connection overhead by reducing the number of TCP/IP packet round trips, and also gives more consistent response time. Using NGINX Amplify, we can easily visualize the interaction, identify bottlenecks, and troubleshoot excessive TCP connect time, improving application performance.
Introduction
Keepalive connections can significantly boost performance, but only if they’re reused extensively enough to sharply reduce the need to create new connections, which are computationally expensive to set up. The performance boost from using keepalives is increased when SSL/TLS is in use, as SSL/TLS connections are even more expensive than insecure connections. (In fact, because keepalives can so greatly reduce the performance penalty otherwise incurred when using SSL/TLS, the extensive use and reuse of keepalives can make the difference as to whether SSL/TLS use is practical or impractical on a website.)
The HTTP Keepalive Connections and Web Performance blog post covers a variety of topics related to the internals of the TCP protocol, as well as a number of common problems, and how to troubleshoot them – including a useful definition of keepalive connections:
HTTP uses a mechanism called keepalive connections to hold open the TCP connection between the client and the server after an HTTP transaction has completed. If the client needs to conduct another HTTP transaction, it can use the idle keepalive connection rather than creating a new TCP connection. Clients generally open a number of simultaneous TCP connections to a server and conduct keepalive transactions across them all. These connections are held open until either the client or the server decides they are no longer needed, generally as a result of an idle timeout.
The Overcoming Ephemeral Port Exhaustion in NGINX and NGINX Plus blog post describes how to make NGINX reuse previously established TCP connections to upstreams [in this case NGINX or NGINX Plus is the client]:
A keepalive connection is held open after the client reads the response, so it can be reused for subsequent requests. Use the keepalive directive to enable keepalive connections from NGINX Plus to upstream servers, defining the maximum number of idle keepalive connections to upstream servers that are preserved in the cache of each worker process. When this number is exceeded, the least recently used connections are closed. Without keepalives, you’re adding more overhead, and being inefficient with both connections and ephemeral ports.
Also, in the 10 Tips for 10x Application Performance blog post, there’s general information about the usefulness and applicability of the client‑side keepalive and upstream‑side keepalive techniques. Note that you use and manage client‑side keepalives and upstream keepalives differently:
- Client‑side keepalives – Client‑side keepalive connections reduce overhead, especially when SSL/TLS is in use. For NGINX, you can increase the maximum number of
keepalive_requestsa client can make over a given connection from the default of 100, and you can increase thekeepalive_timeoutto allow the keepalive connection to stay open longer, resulting in faster subsequent requests. - Upstream keepalives – Upstream connections (connections to application servers, database servers, and so on) benefit from keepalive connections as well. For upstream connections, you can increase the value of the
keepalivedirective, which sets the number of idle keepalive connections that each worker process keeps open to backend servers. This forms a pool of upstream keepalive connections, allowing for increased connection reuse and cutting down on the need to open new connections. The keepalive blog post mentioned above provides technical insights on how to use the upstream keepalive connection pool to optimize application performance.
There are two common cases where an upstream keepalive pool is especially beneficial:
- The application infrastructure has fast application backends that produce responses in a very short time, usually comparable to the speed of completing a TCP handshake. This is because the cost of the TCP handshake is high in relation to the cost of the response.
- The backends in the application infrastructure are remote (from the perspective of NGINX acting as a proxy); therefore network latency is high, as a TCP handshake takes a long time.
Other beneficial side effects of using upstream keepalives include reducing the number of sockets in TIME‑WAIT state, less work for the OS to establish new TCP connections, and fewer packets on the network. However, these are unlikely to result in measurable application performance benefits in a typical setup.
Testing Setup
While using keepalives can be useful, configuring them is usually a bit complex and error prone. We‘ll use Wireshark to inspect the low‑level network elements, such as TCP streams and their connection states.
To measure the TCP connection time, we’ll configure an NGINX container with the NGINX Amplify agent to collect all necessary data. We’ll then use NGINX Amplify to analyze this data. We’ll use siege as the HTTP benchmarking tool with the following configuration (in ~/.siege/siege.conf):
protocol = HTTP/1.1
cache = false
connection = keep-alive
concurrent = 5
benchmark = trueThe connection = keep-alive statement means that the client uses the client‑side HTTP keepalive mechanism. Having it configured that way, we demonstrate that there are two distinct TCP connections – two TCP streams, to be precise – when proxying a request. One is the client‑side HTTP keepalive connection to the NGINX proxy, and the other one is the upstream connection between NGINX and the upstream backend. The latter is part of NGINX keepalive connection pool. In the remainder of this blog post, we’ll talk about upstream keepalive connections only.
We’ll begin with showing the benchmark results in the NGINX Amplify dashboard, and then explain them. This will give you some context about the focus of this exercise.
The testing scenario was to run a series of five siege tests initiated from inside the NGINX container, with each test taking 10 minutes to finish. The tests correspond to scenarios A through E discussed below.
siege -b -t 10m http://127.1/upstream-close/proxy_pass_connection-close/server_keepalive_timeout-0
siege -b -t 10m http://127.1/upstream-close/proxy_pass_connection-keepalive/server_keepalive_timeout-0
siege -b -t 10m http://127.1/upstream-close/proxy_pass_connection-keepalive/server_keepalive_timeout-300
siege -b -t 10m http://127.1/upstream-keepalive/proxy_pass_connection-keepalive/server_keepalive_timeout-0
siege -b -t 10m http://127.1/upstream-keepalive/proxy_pass_connection-keepalive/server_keepalive_timeout-300In this case, we broke a rule of performance testing by running the load generator on the system under test, with the risk of distorting the results. To reduce this effect, we isolated resource use by running and inspecting the traffic in Docker containers. Also, there weren’t many locking operations such as I/O, which both use lots of time and have significant variability unrelated to the system aspects being tested. The fact that the results were pretty consistent seems to indicate that we were able to get relatively “clean” results.
The NGINX Amplify dashboard in the following screenshot includes graphs for the following six metrics. We have omitted the nginx. prefix that NGINX Amplify prepends on each metric name, to match the labels on the graphs:
upstream.connect.time –Time to establish connection to upstream |
upstream.response.time –Time to receive response from upstream |
|
http.request.time –Time to completely process request |
upstream.header.time –Time reading headers in upstream response |
|
http.request.body_bytes_sent –Bytes sent to client, not including headers |
upstream.request.count –Number of requests sent to upstream |
For each metric, three measurements are shown: 50pctl (median), 95pctl, and max. The top four graphs are metrics where lower values represent better performance. The bottom two graphs are traffic‑volume metrics where higher values are better.

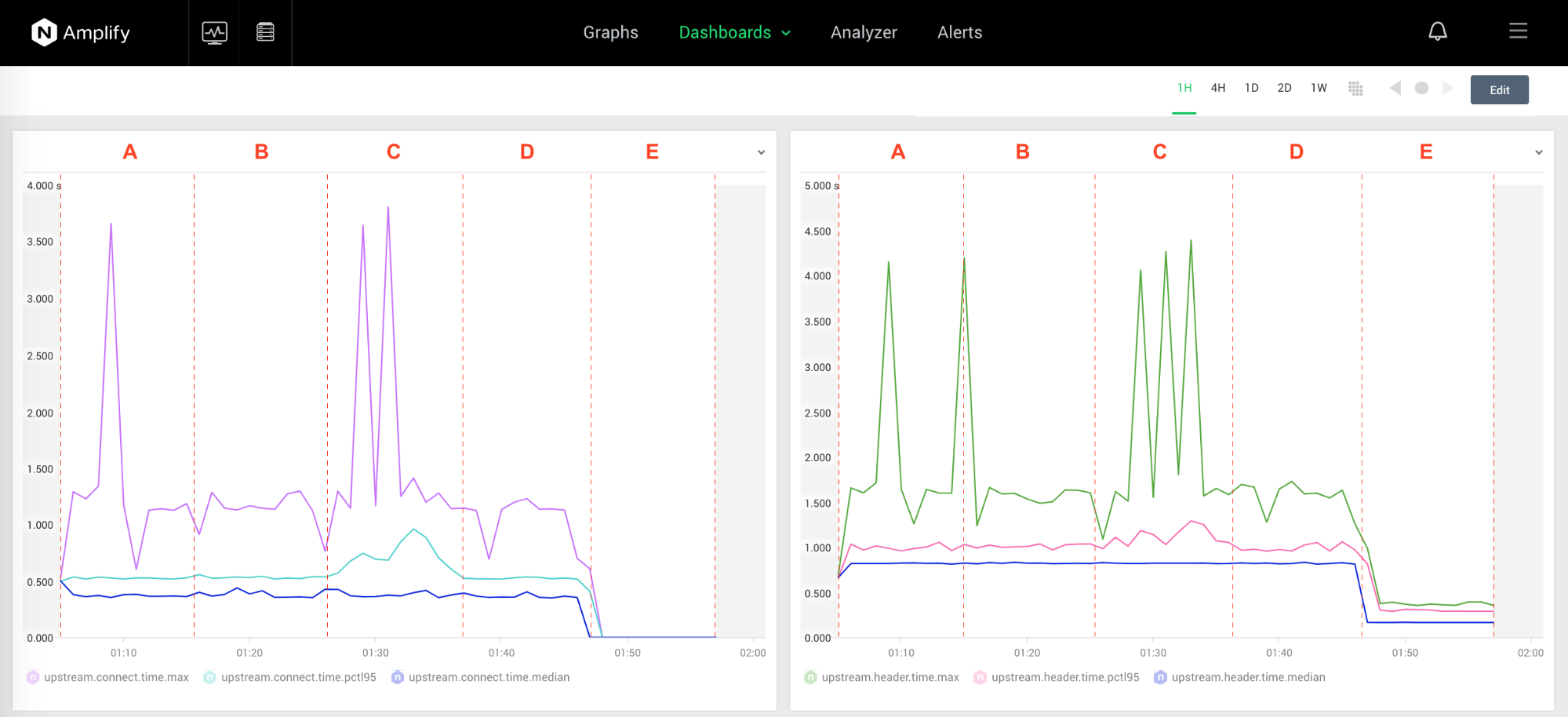
The next screenshot zooms in on the two most important metrics for measuring upstream keepalive performance, upstream.connect.time and upstream.header.time (these correspond to the top‑left and middle‑right graphs in the previous screenshot):
The NGINX Amplify agent was downloaded from the official repo and installed in the NGINX container:
$ docker run --net network0 --name nginx -p 80:80 -e API_KEY=$AMPLIFY_API_KEY -d nginx-amplifyEvery run of the siege benchmark requires two TCP streams: one siege ↔ NGINX and the other NGINX ↔ upstream backend server.
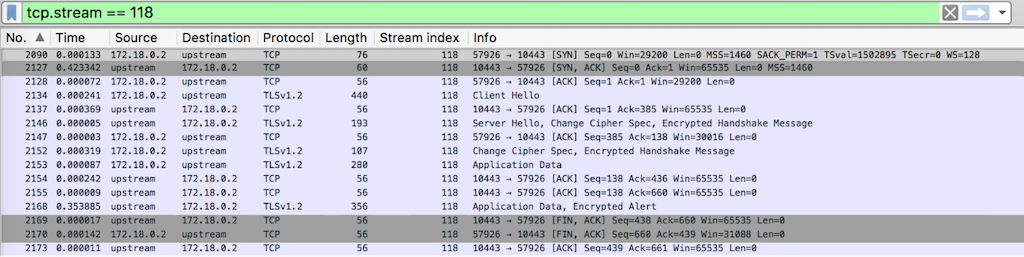
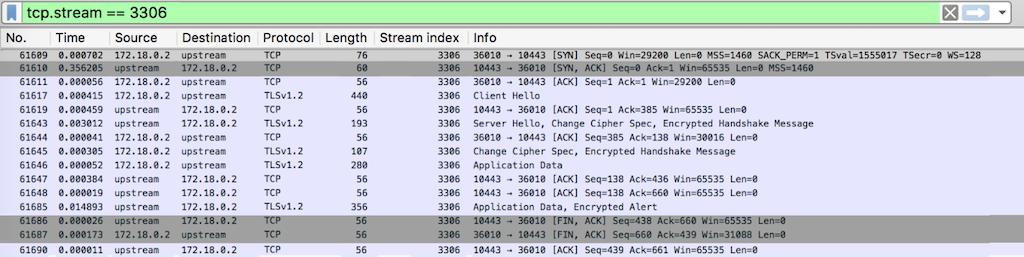
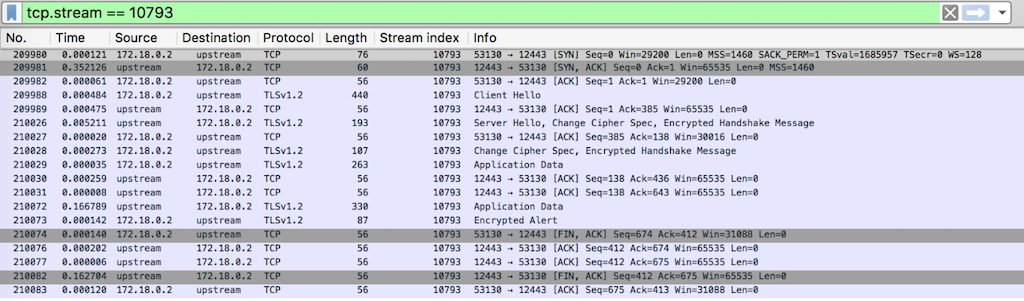
We analyzed the upstream keepalive TCP streams in each of five configuration scenarios (A through E). For the complete NGINX configuration snippets and Wireshark dumps (which also appear below), see this GitHub gist.
Scenarios A, B, and D were tested against an upstream backend server (also running NGINX) configured as follows to disable keepalive connections:
server {
location / {
empty_gif;
keepalive_timeout 0;
}
}Scenarios C and E were tested against an upstream backend NGINX server configured as follows to enable keepalive connections, also increasing their duration and the maximum number of requests serviced over a given connection (the defaults are 75 seconds and 300 respectively):
server {
location / {
empty_gif;
keepalive_timeout 300;
keepalive_requests 100000;
}
}To run Wireshark, we used a tcpdump Docker container and a copy of Wireshark installed on MacOS:
$ docker run --net=container:nginx crccheck/tcpdump -i any --immediate-mode -w - | /usr/local/bin/wireshark -k -i -;Test Results
Let’s take a look at the TCP streams between the NGINX proxy and the upstream server for each of the above‑mentioned scenarios.
Scenario A – upstream‑close / proxy_pass_connection‑close / server_keepalive_timeout‑0
Scenario B – upstream‑close / proxy_pass_connection‑keepalive / server_keepalive_timeout‑0
Scenario C – upstream‑close / proxy_pass_connection‑close / server_keepalive_timeout‑300
Scenario D – upstream‑keepalive / proxy_pass_connection‑keepalive / server_keepalive_timeout: 0
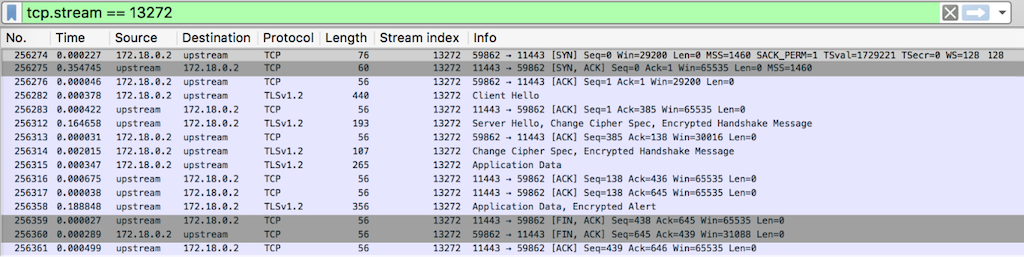
Scenario E – upstream‑keepalive / proxy_pass_connection‑keepalive / server_keepalive_timeout‑300
According to Section 3.5 of RFC‑793: A TCP connection may terminate in two ways: (1) the normal TCP close sequence using a FIN handshake, and (2) an “abort” in which one or more RST segments are sent and the connection state is immediately discarded. If a TCP connection is closed by the remote site, the local application MUST be informed whether it closed normally or was aborted.
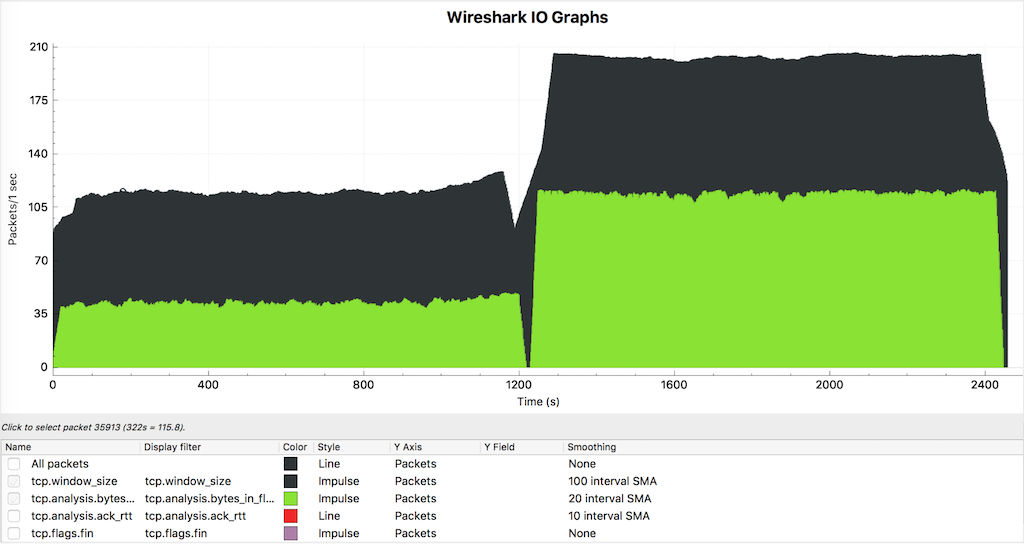
Here’s the Wireshark I/O graph, with the TCP congestion window in dark green, and bytes‑in‑flight in light green:

Now we can see that the upstream keepalive configuration has to contain an upstream keepalive, a proxy connection header as an empty string, with proxy protocol HTTP/1.1. The upstream backend server must support HTTP keepalive connections too, or else TCP connections are closed after every HTTP request.
Test Results Under Load
The results above are from benchmarking against an idle server (located on AWS, EU West → US West). We then performed the same procedure for a heavily loaded server and the same regions (AWS EU West → US West). We performed the same benchmark for two more test cases.
For the loaded server, the testing scenario was to run two siege tests sequentially, again initiated from inside the NGINX container. This time each test took about 20 minutes to finish. The tests correspond to scenarios A and B discussed below.
siege -b -t 20m http://127.1/upstream-heavy-loaded-close/
siege -b -t 20m http://127.1/upstream-heavy-loaded-keepalive/This screenshot shows graphs for the same six metrics as above, this time for the two new scenarios with a heavily loaded server:
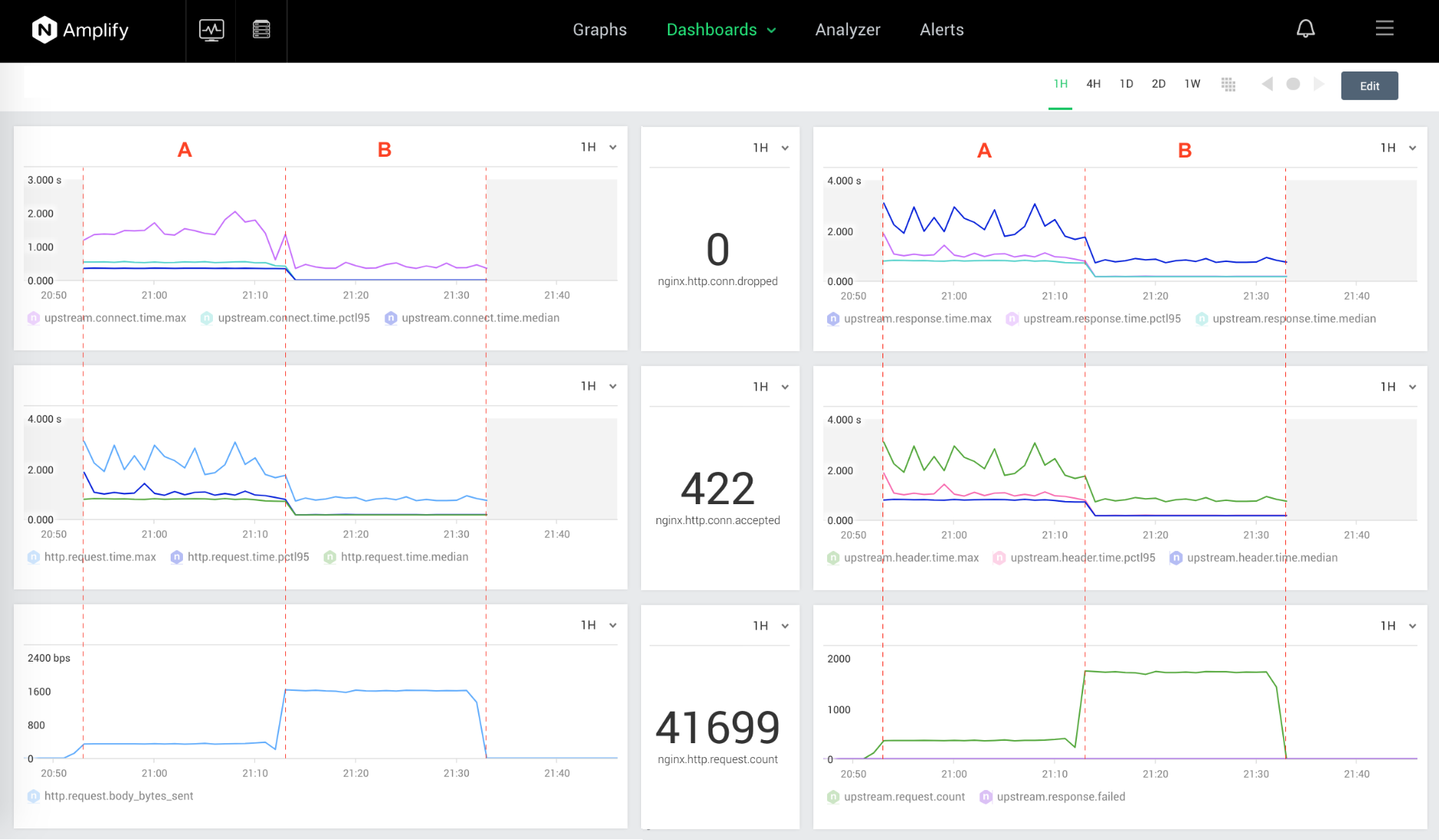
One key result appears in the bottom right graph: with keepalive connections between the NGINX proxy and a heavily loaded backend located far away (Scenario B), the throughput jumps nearly five times compared to no keepalives (Scenario A): upstream.request.count increased from 370 to 1731 requests per minute.
And again let’s zoom in on the two most important metrics, upstream.connect.time and upstream.header.time.
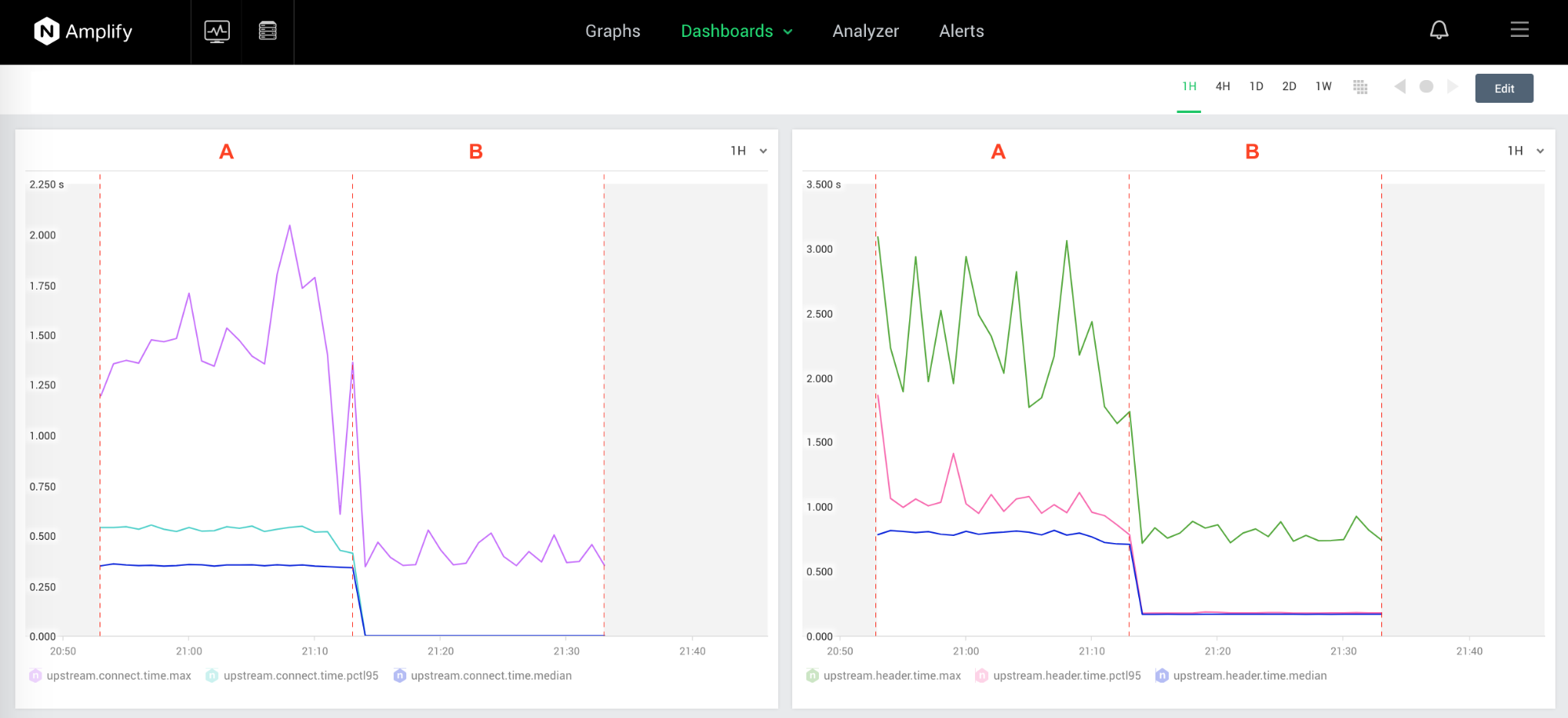
Note that in Scenario B (keepalive connections), the value of upstream.connect.time (the max value out of the statistical distribution collected) is evenly distributed. However, it’s not a zero as it was in the parallel scenario with an idle server (Scenario E above), because the server’s keepalive_requests are configured to 300, and we see FINs followed by SYN/ACKs; we didn’t see that as often in the previous tests, when keepalive_requests were set to a higher value. But given the number of siege runs, we see the 95th‑percentile and the mediam (50th‑percentile) values are 0, which saves client and server resources on the SYN/ACK handshake and the TLS exchange.
In Scenario B, the 95th‑percentile and mean (50th‑percentile) values are same for both upstream.connect.time and upstream.header.time. It’s a very interesting fact, which can possibly be interpreted this way: by reducing the round‑trip time (RTT) we have less connection overhead, and that provides more consistent response time.
The Wireshark TCP streams analyses are very similar to those with the idle server:
Scenario A (load) – upstream‑close / proxy_pass_connection‑close (gist here)
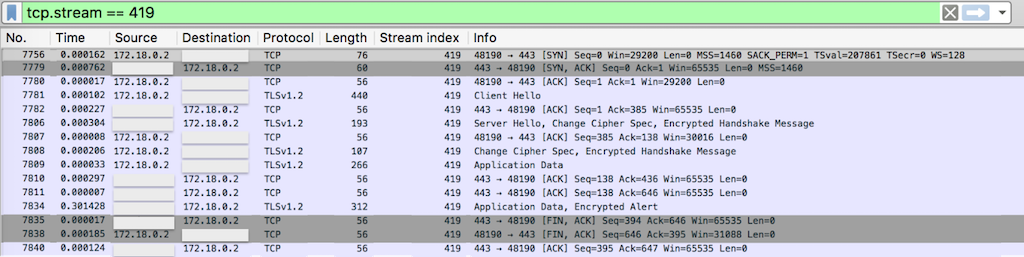
Scenario B (load) – upstream‑keepalive / proxy_pass_connection‑keepalive (gist here)
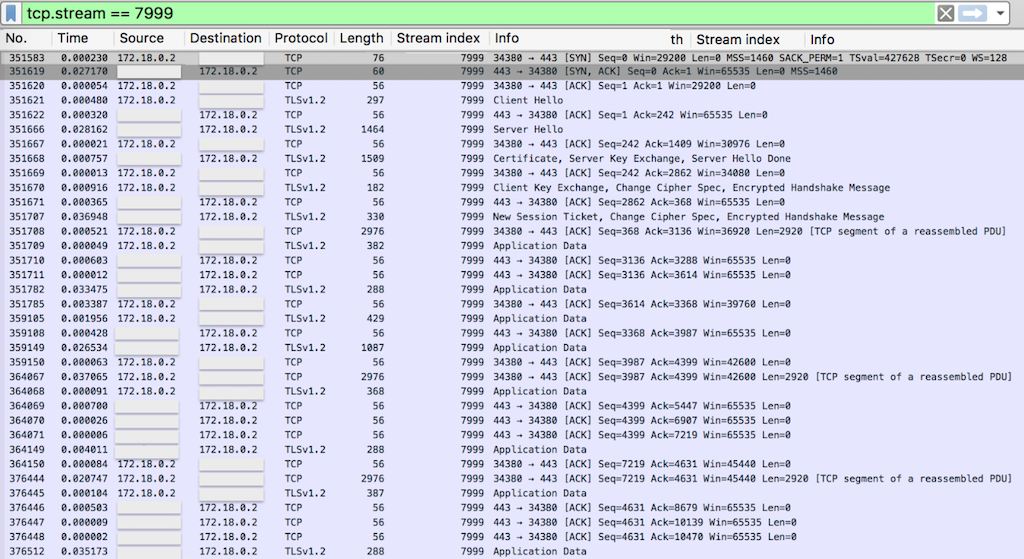
The I/O graph looks similar, too:
As an extra benefit, in a situation where you have more than one upstream backend server, you can use the least_time directive to avoid querying the slower origin server. [Editor – The Least Time load‑balancing method is available in NGINX Plus.]
Key Findings
To summarize our findings from this testing effort:
- The TCP congestion window and bytes‑in‑flight can be increased by using TCP keepalives; the factor depends on round‑trip time. For EU West (client) → US West (origin), performance at least doubles.
- The NGINX upstream keepalive mechanism reduces connection overhead – in a nutshell, there are fewer TCP/IP packet round trips – and also gives consistent response time. Using NGINX Amplify helps visualize this in a no‑hassle manner.
- NGINX Amplify serves as a powerful tool that helps to identify bottlenecks and to troubleshoot excessive TCP connect time, which would otherwise affect application performance.
NGINX Amplify is free for up to five monitored instances of NGINX or NGINX Plus. Sign up to get started.






