

This post is adapted from a presentation at nginx.conf 2017 by Alexey Ivanov of Dropbox. You can view the complete presentation on YouTube.

Table of Contents
| Introduction | |
| 1:45 | Disclaimers |
| 3:13 | Hardware |
| 4:30 | Kernel |
| 7:20 | Network Cards | 11:40 | Network Stack |
| 14:45 | Sysctl Tuning Do’s and Don’ts |
| 16:10 | Libraries |
| 18:13 | TLS |
| 20:42 | NGINX |
| 22:30 | Buffering |
| 24:41 | TLS with NGINX |
| 28:10 | Event-Loop Stalls |
| 30:15 | Wrapping Up |
| 33:05 | Q&A |
Introduction
Alexey Ivanov: First, let me start with a couple of notes. This presentation will move fast, really fast, and it’s a bit dense. Sorry about that. I just needed to pack a lot of stuff into a 40‑minute talk.
![]()
A transcript of this talk is available on the Dropbox Tech Blog. It’s an extended version with examples of how to profile your stuff, how to monitor for any issues, and how to verify that your tuning has worked. If you like this talk, go check out the blog post. It should be somewhere at the top of Hacker News by now. Seriously, go read it. It has a ton of stuff. You might like it.

About me, very quickly: I was an SWE [software engineer] at Yandex.Storage. We were mostly doing high‑throughput stuff. I was an SRE [site reliability engineer] at Yandex.Search. We were mostly doing low‑latency stuff. Now, I’m an SRE for Traffic at Dropbox, and we’re doing both of these things at the same time.

About Dropbox Edge: it’s an NGINX‑based proxy tier designed to handle low‑latency stuff – website views, for example – along with high‑throughput data transfers. Block uploads, file uploads, and file downloads are high‑throughput data types. And we’re handling both of them with the same hardware at the same time.
1:45 Disclaimers
A few disclaimers before we start:

This is not a Linux performance analysis talk. If you need to know more about eBPF [enhanced Berkeley Packet Filter], perf, or bcc, you probably need to read Brendon Gregg’s blog for that.

This is also not a compilation of TLS best practices. I’ll be mentioning TLS a lot, but all the tunings you apply will have huge security implications, so read Bulletproof SSL and TLS by Ivan Ristić or consult with your security team. Don’t compromise security for speed.
This is not a browser‑performance talk, either. The tunings that’ll be described here will be mostly aimed at server‑side performance, not client‑side performance. For background, read High Performance Browser Networking by Ilya Grigorik.
Last, but not least, the main point of the talk is: do not cargo‑cult optimizations. Use the scientific method: apply stuff and verify each and every tunable yourself.
We’ll start the talk with the lowest layers of the stack, and work our way up to the software, including NGINX.
3:13 Hardware
At the lowest layer, we have hardware.

When you’re picking your CPU, try looking for AVX2‑capable CPUs. You’ll need at least the Haswell microarchitecture. Ideally, you’ll need Broadwell, or Skylake, or the more recent Epyc, which also has a good performance.

For lower latencies, avoid NUMA [non‑uniform memory access]. You’ll probably want to disable HT. If you still have multi‑node servers, try utilizing only a single node. That will help with latencies on the lowest levels.

For higher throughput, look for more cores. More cores are generally better. Maybe NUMA isn’t that important here.

For NICs, 25G or 40G NICs are probably the best ones. They don’t cost that much; you should go for them. Also, look for active mailing lists and communities around drivers. When you’ll be troubleshooting driver issues, that’ll be very important.

For hard drives, try using Flash-based drives. If you’re buffering data or caching data, that‘ll also be very important.
4:30 Kernel
Let’s move to the kernel stuff.

Right in between the kernel and your hardware, there will be firmware and drivers. The rule of thumb here is upgrade frequently, but slowly. Don’t go bleeding edge; stay a couple of releases behind. Don’t jump to major versions when they’re just released. Don’t do dumb stuff, but update frequently.
Also, try to decouple your driver updates from your kernel upgrades. That will be one thing less to troubleshoot, one thing less to think about when you upgrade your kernel. For example, you can pack your drivers with DKMS [Dynamic Kernel Module Support] or prebuilt drivers for all your kernel versions. Decoupling really helps troubleshooting.

On the CPU side, your main tool will probably be turbostat, which allows you to look into the MSR [model‑specific registers] of the processor and see what frequencies it’s running at.
If you’re not satisfied with the time the CPU spends in idle states, you can set [the Linux CPUfreq] governor to performance. If you’re still not satisfied, you can set x86_energy_perf_policy to performance. If the CPU is still spending a lot of time in idle states, or you’re dropping packets for some reason, try setting cpu_dma_latency to zero. But that’s for very low‑latency use cases.

For the memory side, it’s very hard to give generic memory‑management advice, but generally, you should set THP [Transparent Huge Pages] to madvise. Otherwise, you may accidentally get a 10x slowdown when you’re going for a 10% to 20% increase in speed. Unless you went with utilizing a single NUMA node, you probably want to set vm.zone_reclaim_mode to zero.

Returning to the topic of NUMA [non‑uniform memory access], that’s a huge subject, really huge. It all comes down to how all modern servers are really multiple servers locked together in single silicon. [To deal with NUMA], you can:
- Ignore it – disable it in BIOS – and get just mediocre performance across the board.
- Deny it – for example by specifically using single‑node servers. That’s probably the best case, if you can afford it.
- Embrace it and try to treat each and every NUMA node as a separate server with separate PCI Express devices, separate CPUs, and separate memory.
7:20 Network Cards
Let’s move to network cards. Here, you’ll mostly be using eth2. You’ll be using it to look at your hardware stats and to tune your hardware at the same time.

Let’s start with ring buffer sizes. The rule of thumb here is that more is generally better. There are lots of caveats to that, but bigger ring buffers will protect you against some minor stalls or packet bursts. Don’t increase them too much, though, because that will also increase cache pressure, and on older kernels, you will incur bufferbloat.

The next thing is to tune interrupt affinity for low latency. You should really limit the number of queues you have to a single NUMA node, select a NUMA node where your network card is terminated physically, and then pin all these queues to the CPUs, one to one.

For high‑throughput stuff, generally it’s OK to just spread interrupts across all of your CPUs. There are, once again, some caveats around that: you may need to tune stuff a bit, for example by bringing up interrupt processing on one NUMA node and your application on other NUMA nodes – but just verify it yourself. You have that flexibility.

To achieve low latency with interrupt coalescing, generally you should disable adaptive coalescing, and you should lower [the values of] microseconds [rx‑usecs] and frames [rx‑frames]. Just don’t set them too low. If you set them too low, you’ll get an interrupt problem and it will actually increase your latencies.

To achieve high throughput with interrupt coalescing, you can either depend on the hardware to do the right thing, such as enabling adaptive coalescing, or just increase microseconds and frames to some particularly large value, especially if you have huge string buffers – that will also help.

About hardware offloads inside the NIC – the recent NICs are very smart. I could probably give a separate talk just about hardware offloads, but there are still a few rules of thumb you can apply:
- Don’t use LRO [large receive offload]; use GRO [generic receive offload]. LRO will break stuff miserably, especially on the router side.
- Be careful with TSO [TCP segmentation offload]: it can corrupt packets, it may stall your network card – stuff may break. TSO is very complicated. It’s in hardware, so it’s highly dependent on firmware‑version drivers. GSO [generic segmentation offload], on the other hand, is OK.
- But with older kernel versions of kernels, both TSO and GSO can lead to bufferbloat. Be careful there also.

About packet steering: on modern hardware, it’s generally OK to rely on the network card to do the right thing. If you have old hardware – for example, some 10G cards can only RSS [do receive‑side scaling] to the first 16 queues, so if you have 64 CPUs, they [10G cards] won’t be able to steer packets across all of them.
On the software side, you have RPS [receive packet steering]. If your hardware can’t steer packets efficiently, you can still do it in software. For example, use RPS and spread packets across more CPUs. Or, if your hardware can’t RSS the traffic type you’re using (for example, IPinIP or GRE tunneling), then again, RPS can help.
XPS [transmit packet steering] is generally OK to enable.
11:40 Network Stack
Now we’re up to the network stack.

This is a great picture stolen from Making Linux TCP Fast, by the people who brought you BBR [Bottleneck Bandwidth and RTT] and Linux network‑stack performance improvements for the last four years. It’s a great paper. Go read it. It’s fun to read. It’s a very good summary of a huge topic.
We’ll start with the lowest levels [of the network stack] and go up.

Fair queuing is responsible for sharing bandwidth fairly across multiple flows, as the name implies.
Pacing spreads packets within the flow according to a sending rate set by a congestion‑control protocol.
Combining fair queuing and pacing together is a requirement for BBR, but you can also do it with CUBIC, for example, or on any other congestion‑control protocol. It greatly decreases retransmit rates. We’ve observed decreases of 15% to 25%, which improves performance. Just enable it: again, free performance.

There’s been a lot of work done in this area of congestion control: some by Google, some by Facebook, and some by universities [CAIA is the Centre for Advanced Internet Architectures at Swinburne University of Technology in Australia]. People are usually using tcp_cubic by default.
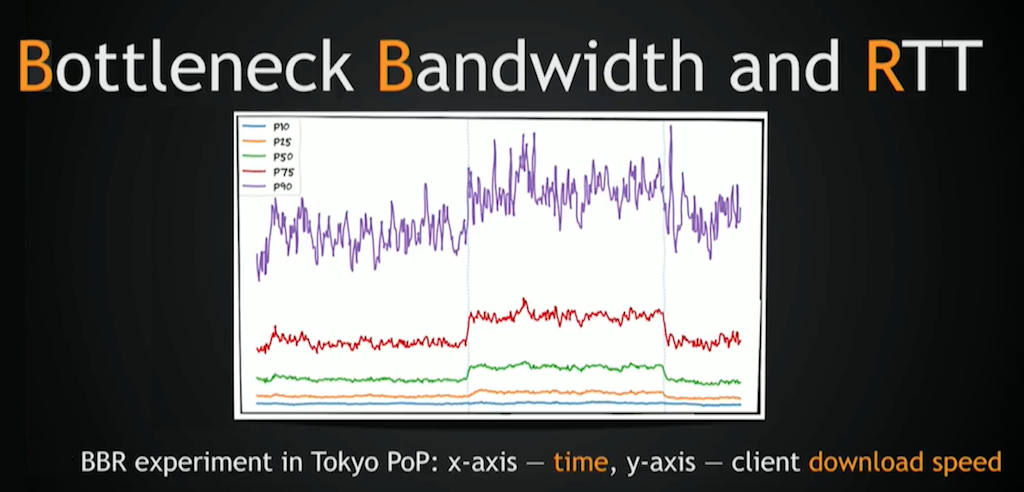
We’ve been looking at BBR for quite a long time, and this is data from our Tokyo PoP. We did a six‑hour BBR experiment some months ago, and you can see that download speed went up for pretty much all percentiles. The clients we considered were bandwidth‑limited, basically TCP‑limited in some sense, or congestion control‑limited.

Let’s talk about ACK processing and loss detection. I come back again to a very frequent theme in my talks: use newer kernels. With newer kernels, you get new heuristics turned on by default, and old heuristics are slowly retired.
You don’t need to do anything; you upgrade your kernel and you get the benefit of the new heuristics for free. So, upgrade your kernel. Again, it doesn’t mean that you have to be on the bleeding edge. Use the same guidelines as for firmware and drivers apply: upgrade slowly, but frequently.
14:45 Sysctl Tuning Do’s and Don’ts

You can’t actually do any network optimization talk without mentioning sysctl. Here are some do’s and don’ts.

Let’s start with stuff you shouldn’t do:
- Don’t enable
TIME‑WAITrecycle. It was already broken for NAT [Network Address Translation] users; it will be even more broken in newer kernels. And it’ll be removed, so don’t use it. - Don’t disable timestamps unless you know what you’re doing. It has very non‑obvious implications, for example for
SYNcookies. And there are many such implications, so unless you know what you’re doing – unless you’ve read the code – don’t disable them.

Stuff you should do, on the other hand:
- You should probably disable
net.ipv4.tcp_slow_start_after_idle. There’s no reason to keep it on. - You should enable
net.ipv4.tcp_mtu_probingjust because the Internet is full of ICMP [Internet Control Message Protocol] black holes. - Bump up read and write memory [
net.ipv4.tcp_{r,w}mem]. Not too much, though, just match it to BDP [the Bandwidth Delay Product]. Otherwise, you may get built‑in kernel locking[?].
16:10 Libraries
Now we’re at the library level. We’ll discuss the commonly used libraries in web servers.
All the previous tunings were basically applicable to pretty much any high‑load network server; these are more web‑specific.

One web‑specific tuning; if you notice – and only if you notice – that NGINX or any other web server is spending a lot of time doing compression or deflate symbols (when you run perf top, you see deflate in the output), then maybe it’s time to switch to a more optimized versino of zlib. Intel and Cloudflare both have zlib forks, for example.

If you see problems around malloc – you see memory fragmentation or that malloc is taking more time than it should – then you can switch your malloc implementation to jemalloc or tcmalloc.
That also has the great benefit of decoupling your application from the operating system. It has its drawbacks, of course, but generally, you don’t want to troubleshoot new malloc behavior when you (for example) switch operating systems or upgrade your operating system. Decoupling is a good thing. You’ll also get the introspection profile, and stats and stuff.

If you see PCRE [Perl Compatible Regular Expressions] symbols in output from perf top, then maybe it’s time to enable JIT [just‑in‑time compilation]. I would say it’s a bit questionable. If you have lots of regular expressions in your configs, maybe you need to just rewrite them. But again, you can enable JIT and see how it behaves in your particular workload.
18:13 TLS

TLS is a huge subject, but we’ll try to quickly cover it. First, you start by choosing your TLS library. Right now, you can use OpenSSL, LibreSSL, and BoringSSL. There are other forks, of course, but the general idea is that the library you choose will greatly affect both security and performance, so be careful about that.

Let’s talk about symmetric encryption. If you’re transferring huge files, then you’ll probably see OpenSSL symbols in output from perf top. Here, I can advise you to enable ChaCha20-Poly1305.
First, it will diversify your cipher suites. You will not be AES‑only, which is good [not to be].
Second, if your library supports it, you can enable equal preference cipher groups and let the client decide which ciphers to use. For example, your server will still dictate the order of preference, but within the same group, the client can decide. For example, low‑speed mobile devices will pick ChaCha instead of AES because they don’t have hardware support for AES.

For asymmetric encryption, you should use ECDSA certs along with your RSA certs, just because they’re ten times faster on the server side.
Another piece of advice: don’t use uncommon crypto parameters. Let me elaborate on this. First of all, uncommon crypto is not really the best one from a security standpoint, so you should use it only if you know what you’re doing. Second, a great example is 4K RSA keys, which are ten times slower than 2K RSA keys. Don’t use them unless you really need them, unless you want to be ten times slower on the server side. Again, the rule of thumb here is that the most common script is the most optimized one. The crypto that is used most will be the most optimized.
20:42 NGINX
Finally, we’re up to the NGINX level. Here, we’ll talk about NGINX‑specific stuff.

Let’s start with compression. Here, you need to decide first what to compress. Compression starts with the mime.types file and NGINX gzip_types directive. You can probably just auto‑generate the values from mime-db and have all the types defined so NGINX knows about all registered MIME types.

Then, you need to decide when to compress stuff. I wrote a post on the Dropbox Tech Blog about deploying Brotli for static content at Dropbox. The main idea is that if your data is static, you can precompress it to get the maximum possible compression ratios. It will be free because it’s an offline operation; it’s part of your static build step.

How to compress is also a question. You can use gzip. There is a third‑party Brotli module for NGINX. You can use them both. You also need to decide on compression levels. For example, for dynamic stuff you need to optimize for full round‑trip time. Round‑trip time means encryption, transfer, and decryption, which means maximum compression levels are probably not the right thing for dynamic content.
22:30 Buffering
Buffering: there’s lots and lots of buffering along the way from your application through NGINX to the user, starting from socket buffers to library buffers, such as gzip or TLS. But here, we’ll only discuss NGINX internal buffers, not library buffers or socket buffers.

Buffering inside NGINX has its pros. For example, it has backend protection, which means if client sends you data byte by byte, then NGINX won’t hold the backend thread; it will get the full request and send it to the backend. On the response side, it’s the same. If your client is malicious and requests one byte at a time from you, NGINX will buffer the response from your backend and free up that backend thread, which can then do useful work.
So, buffering has its pros. It makes it possible to retry requests. On the request side, when you have full requests you can actually retry them against multiple backends in case one request fails.

Buffering also has its cons. It increases latency, but it also increases memory and I/O usage.

Here, you need to decide statically, at config‑generation time, what you want to buffer and what you don’t. This is not always possible. You can’t decide where you want buffering, and then how much buffering, and where you want to buffer in memory, and where you want to buffer on disk. You can always leave it up to an application to decide. You can do that with the X-Accel-Buffering header. On response, your application might say whether it wants the response to be buffered or not.
24:41 TLS with NGINX
We return to the topic of TLS, now with respect to NGINX.

On the NGINX side, you can save CPU cycles both on your client side and on your server side by using session resumption. NGINX supports session resumption through session IDs. It’s widely supported on the client side also, but it requires server‑side state. Each session will consume some amount of memory, and it is local to a box. Therefore, you’ll either need “sticky” load balancing or a distributed cache for these sessions on your server side. And it’s only slightly affects perfect forward secrecy (PFS). So, it’s good.

On the other side, you can use session resumption with tickets. Tickets are mostly supported in browser‑land, on the client. It depends on your TLS library on that side. It has no server‑side state, so it’s basically free. But it highly depends on your key‑rotation infrastructure and the security of that infrastructure. Because of that, it greatly limits PFS. It limits it to a duration of a single ticket key which means that if attackers can get hold of that key, they can retrospectively decrypt all the traffic they collected. Again, there are lots of security implications to any tuning you do at the TLS layer, so be careful about that. Don’t compromise your user’s privacy for performance.

Speaking about privacy, OCSP stapling: you should really just do that. It may shake some RTTs. It can also improve your availability. But mostly, it will protect your user’s privacy. Just do that. NGINX also supports it.

TLS record sizes: the main idea is that your TLS library will break down data into chunks. Until you receive the full chunk, you cannot decrypt it. Therefore, during the config‑generation time, you need to decide what servers are low‑latency and what servers are high‑throughput. If you can’t decide that during the config‑generation phase, then you need to use something like Cloudflare’s patch to NGINX that adds support for dynamic TLS record sizes. It will gradually increase your record sizes as request streams. Of course, you may say, “Why don’t you just set it to 1K?” Because if you set it too low, it will incur a lot of overhead on the network layer and on the CPUs. So, don’t set it too low.
28:10 Event-Loop Stalls
A really huge topic: event‑loop stalls. NGINX has a great architecture. It’s asynchronous and event‑based. It’s parallelized by having multiple share‑nothing (or almost share‑nothing) processes. But when it comes to blocking operations, it can actually increase your tail latency by alot. So, the rule of thumb is do not block inside the NGINX event loop.

A great source of blocking is AIO, especially if you’re not using Flash drives. If you’re using spinning drives, enable AIO with thread pools, especially if you’re using buffering or caching. There is really no reason not to enable it. That way, all your read and write operations will be basically asynchronous.

You can also reduce blocking on log emission. If you notice that NGINX often blocks on log writes, you can enable buffering and gzip for the access_log directive. That won’t fully eliminate blocking, though.

To fully eliminate it, you need to log to syslog in the first place. That way, your log emission will be fully integrated inside the NGINX event loop and it won’t block.

Opening files can also be a blocking operation, so enable open_file_cache, especially if you’re serving a ton of static content or you’re caching data.
30:15 Wrapping Up
This went faster than I thought it would. I skipped the most crucial parts here to make it fit into presentation format and make it fit into 40 minutes. I made a lot of compromises. And I skipped the most crucial parts: how you verify whether you need to apply tuning, and how you verify that it worked. All these tricks with perf, eBPF, and stuff. If you want to know more about that, go check out the Dropbox Tech Blog. It has way more data and a ton of references: to source code, to research papers, and to other blog posts about similar stuff.

Wrapping up: in the talk, we mostly went through single‑box optimizations. Some of them improve efficiency and scalability and remove artificial choke points that your web server may have. Other ones balance latency and throughput, and sometimes improve both of them. But it’s still a single‑box optimization that affects single servers.

In our experience, most performance improvement comes from global optimizations. Good examples are load balancing, internal and external, within your network and around the edge, and inbound and outbound traffic engineering. These are problems that are on the edge of knowledge right now. Even huge companies such as Google and Facebook are just starting to tinker with this, especially outbound traffic engineering. Both companies just released papers on that. This is a very hot subject. It’s full of PID controllers, feedback loops, and oscillations.
If you’re up to these problems, or maybe anything else – after all, we [Dropbox] also do lots of storage – if you’re up for the challenge: yes, we’re hiring; we’re hiring SWEs, SREs, and managers. Feel free to apply.
33:05 Q&A

And finally, Q&A. I’m not sure how much time I have, but let’s see how it goes. Also, I’ll be here today and tomorrow. My Twitter address is @SaveTheRbtz), so feel free to ask me any questions there. [His email address is rbtz@dropbox.com.]
Q: Does the AIO setting affect reads in addition to writes?
A: By default, it [the aio directive] only affects reads. If you enable the aio_write directive, then the setting also affects writes. For example, temp file writes you need to buffer, I think are offloaded through AIO.
Q: What about QuickAssist? Have you tried it?
A: QuickAssist sounds nice, but there are a couple of caveats. It implies that your software needs to know how to talk synchronously to your offload engine.
To answer your question, we have not tried it. Presentation graphs from QuickAssist look awesome, especially around RSA 2K. But again, in the case of SSL handshake offload, it depends on the OpenSSL library having support for asynchronous operations. They vetted it in OpenSSL version 1.1, but nobody is actually using it for now. Also, it requires hacks to NGINX. Intel did a good job at that, and has released patches to NGINX to support asynchronous OpenSSL APIs. I’m not sure anyone is using them in production.
The only use case I see for QuickAssist right now is basically RSA 2K, because ECDSA is very fast on modern CPUs. The processors that I was talking about – such as AVX‑ and BMI‑ and ADX‑capable CPUs, like Broadwell and Epyc – are really good at elliptic curve stuff.
For bulk data transfers, AES‑NI is very fast. You can do almost a gigabyte per second per core. So you don’t need hardware offload there. You will hit other bottlenecks first.
On the compression side, optimized versions of zlib libraries that can use AVX instructions are also very fast.






