

NGINX Plus R9 introduces the ability to reverse proxy and load balance UDP traffic, a significant enhancement to NGINX Plus’ Layer 4 load‑balancing capabilities.
This blog post looks at the challenges of running a DNS server in a modern application infrastructure to illustrate how both NGINX Open Source and NGINX Plus can effectively and efficiently load balance both UDP and TCP traffic. (Application [active] health checks are exclusive to NGINX Plus, but otherwise the information in this blog applies equally to NGINX Open Source; for brevity, we’ll refer to NGINX Plus for the rest of the post).
[Editor – For an overview of all the new features in NGINX Plus R9, see Announcing NGINX Plus R9 on our blog.]
Why Load Balance UDP Traffic?
Unlike TCP, UDP by design does not guarantee the end‑to‑end delivery of data. It is akin to sending a message by carrier pigeon – you definitely know the message was sent, but cannot be sure it arrived. There are several benefits to this “connectionless” approach – most notably, lower latency than TCP both because UDP’s smaller individual messages use less bandwidth and because there is no handshake process for establishing a connection. UDP leaves the problem of detecting timeouts and other network‑level problems to the application developer. But what does this mean for DNS?
Like several other UDP‑based protocols, DNS uses a request‑response data flow. For example, a DNS client asks for the IP address corresponding to a hostname and receives an answer. If a response doesn’t arrive within a given timeout period, the DNS client sends the same request to a “backup” DNS server. However, having to wait the timeout period before retrying a request can turn what is usually an extremely fast process (measured in milliseconds) into a very slow one (measured in seconds).
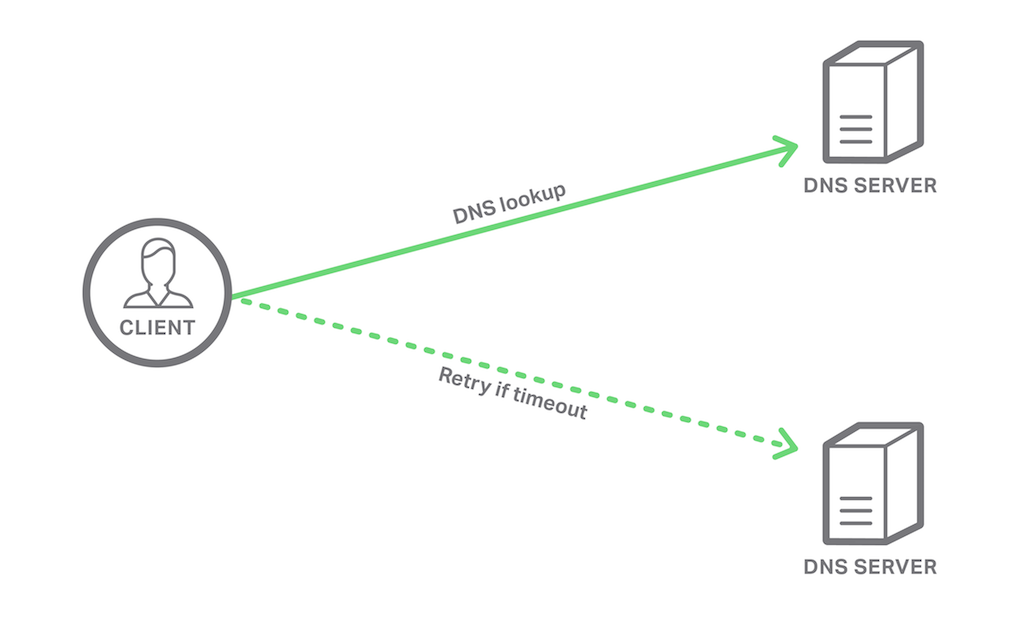
Using NGINX Plus to proxy and load balance DNS traffic reduces the number of occasions where the client experiences a timeout. With multiple DNS servers behind the NGINX Plus load balancer, clients only experience a timeout when there is a network partition between the client and NGINX Plus. Any problems with the DNS servers themselves are not experienced by the client when NGINX Plus uses application health checks. By monitoring the availability and response time of each server, NGINX Plus avoids sending client requests to an unhealthy server.
DNS is Not Only a UDP Protocol
Although the vast majority of DNS traffic is over UDP, there are common DNS operations that use TCP. DNS uses UDP for small messages (up to 512 bytes), but TCP for operations that require (or are likely to require) larger messages. Historically, TCP was used with DNS only for zone transfers from an authoritative, primary name server to its secondary name servers. However, with the shift towards containers and immutable infrastructure, DNS is increasingly used as the primary service discovery mechanism, through use of SRV records.
DNS SRV records were originally introduced for voice over IP (VoIP) handsets using SIP to discover their servers, but can be used for any type of service. However, SRV records include a lot more information than most other DNS record types. As a result, only about 10 SRV records fit in the standard 512 byte UDP response, as opposed to about 30 A records. When a DNS response exceeds the 512 byte limit, the first 512 bytes are returned but the response is flagged as “truncated”. At this point a DNS client can either deal with the truncated response as best it can, or retry the same request using TCP.
This means that when load balancing DNS servers in a modern network infrastructure, NGINX Plus can expect to receive a mix of UDP and TCP traffic.
DNS in a Microservices Environment
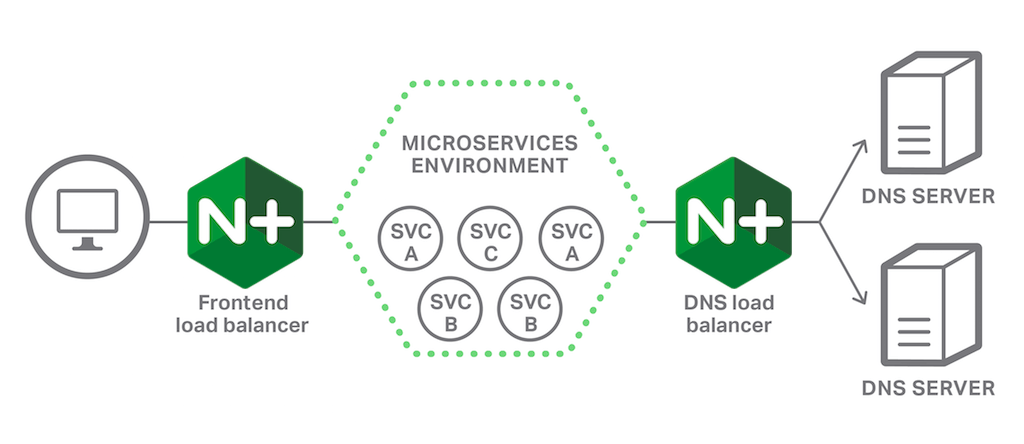
The following illustration shows a simplified view of a microservices environment with two load balancers. The frontend load balancer proxies requests from the public clients of the application, selecting the best microservice instance and performing many other functions that we won’t discuss here. We’ll concentrate on the DNS load balancer, which sits between the microservices environment and the DNS servers that provide service discovery information to the microservices.
Configuring Basic DNS Load Balancing
NGINX Plus implements Layer 4 load balancing in the Stream module, so UDP and TCP load balancing is configured in the stream block as shown in the following snippet.
Warning: You cannot simply add this configuration snippet as a new file in the /etc/nginx/conf.d directory. A validation error results (“stream directive is not allowed here”), because the default NGINX Plus nginx.conf configuration file includes the content of files in the conf.d directory in the http block. The simplest solution is to include the complete stream block directly in nginx.conf.
stream {
upstream dns_servers {
server 192.168.136.130:53;
server 192.168.136.131:53;
}
server {
listen 53 udp;
listen 53; #tcp
proxy_pass dns_servers;
error_log /var/log/nginx/dns.log info;
}
}First we define the upstream group of DNS servers. The server directives specify the port number that our upstream servers are listening on, 53 (the well‑known port for DNS).
The server{} block defines how NGINX Plus handles incoming DNS traffic. The two listen directives tell NGINX Plus to listen on port 53 for both UDP and TCP traffic. TCP is the default Layer 4 protocol for the Stream module, so we don’t explicitly specify it as a parameter as we do for UDP.
The proxy_pass directive tells NGINX Plus what to do with the traffic it is listening for. Here we proxy such traffic to the dns_servers upstream group. NGINX Plus automatically uses UDP when forwarding client UDP requests to upstream servers (and TCP for client TCP requests), so we don’t need to explicitly specify the Layer 4 protocol in the upstream group.
There is no access_log directive in the Stream module, because NGINX Plus does not inspect the payload of TCP segments or UDP datagrams (as it does for HTTP packets). However, we can use the info parameter on the error_log directive to log the connection processing and proxy events.
[Editor – Access logging was enabled in the Stream module after this blog was published, in NGINX Open Source 1.11.4 and NGINX Plus R11.]
Tuning for High Availability
To improve the availability of our DNS servers, we can add a couple more directives and configure active (application) health checks.
Configuring the Number of Proxy Responses and the Timeout Duration
The first additional directive is proxy_responses, which says how many responses NGINX Plus expects for each proxied UDP request. In our case, after receiving a single response NGINX Plus immediately stops waiting for further responses, which frees up the memory and socket used for that session.
The second additional directive, proxy_timeout, determines how long NGINX Plus waits for a response from the server (here we’re reducing the default 10 minutes to 1 second). If NGINX Plus receives no response within this period, it tries the next server in the upstream group and marks the unresponsive upstream server as unavailable for a defined period (10 seconds by default) so that no other clients suffer a timeout‑induced delay during that time.
server {
listen 53 udp;
listen 53; #tcp
proxy_pass dns_servers;
error_log /var/log/nginx/dns.log info;
proxy_responses 1;
proxy_timeout 1s;
}We can also change the amount of time a server is marked as unavailable, by including the fail_timeout option to the server directive in the upstream group. With the following setting, NGINX Plus marks failed upstream servers as unavailable for 60 seconds:
upstream dns_servers {
server 192.168.136.130:53 fail_timeout=60s;
server 192.168.136.131:53 fail_timeout=60s;
}This allows us to control how much delay a client experiences should one of our DNS servers fail. However, if a TCP request is attempted to a failed DNS server then the inherent error checking in TCP allows NGINX Plus to automatically mark it as unavailable so that subsequent requests for TCP or UDP to that server will be avoided.
Configuring Active Health Checks
The active health check feature in NGINX Plus is an additional and extremely valuable tool for high availability of any load‑balanced service, including DNS. Rather than waiting for an actual TCP request from a DNS client to fail before marking the DNS server as down, we have NGINX Plus periodically attempt a TCP connection on port 53 to establish whether the DNS server is both up and working correctly, by including the health_check directive with its port=53 parameter in the server{} block. (NGINX Plus by default sends health checks to the port specified by the listen directive, 53 in our case. So here we’re using the parameter to configure the default explicitly, but we could specify a different port if we also modified our DNS servers to respond to traffic on it.)
With UDP, we can go one step further and configure an active health check that makes a real DNS lookup for a known record. For example, we might place the following CNAME record in the zone file for the same subdomain as is used for service discovery within the microservices environment.
healthcheck IN CNAME healthy.svcs.example.com.Given the lightweight nature of UDP, we can watch network traffic and easily extract the string of bytes that represents a DNS lookup. Then we create a match configuration block with that string as the parameter to the send directive. The expect directive specifies the response the server must return to be considered healthy.
match dns_lookup {
send x00x01x00x00x00x01x00x00x00x00x00x00x06x68x65x61 ...;
expect ~* "healthy.svcs.example.com.";
}The benefit of this deep, application‑level health check is that even if your name server is up and running, performing a real DNS lookup for your production domain uncovers configuration problems and data corruption that might otherwise cause problems downstream.
The NGINX Plus Support team can help with preparing UDP health checks for DNS lookups and other protocols.
The following snippet highlights the additional directives required for active health checks.
stream {
upstream dns_servers {
zone dns_mem 64k;
server 192.168.136.130:53 fail_timeout=60s;
server 192.168.136.131:53 fail_timeout=60s;
}
match dns_lookup {
send x00x01x00x00x00x01x00x00x00x00x00x00x06x68x65x61 ...;
expect ~* "healthy.svcs.example.com.";
}
server {
listen 53 udp;
listen 53; #tcp
health_check match=dns_lookup interval=20 fails=2 passes=2 udp;
health_check interval=20 fails=1 passes=2 port=53; #tcp
proxy_pass dns_servers;
error_log /var/log/nginx/dns.log debug;
proxy_responses 1;
proxy_timeout 1s;
}
}The zone directive defines a shared memory zone called dns_mem, which makes the results of health checks (and other state information) available to all of the NGINX Plus worker processes.
The match directive is discussed just above.
The health_check directive has a number of parameters you can tune for your environment. Here we define separate health checks for UDP and TCP respectively. Because of the difference between UDP and TCP, we require two successive UDP health‑check failures before marking the DNS server as unhealthy, but only one TCP failure. For both protocols we require two successful responses before marking a server as healthy again, to avoid sending requests to an unstable, “flapping” server.
An advantage of defining a single upstream group of DNS servers for both UDP and TCP traffic is that a failed health check for either protocol marks the server as unhealthy and removes it from the load‑balanced pool.
Tuning for Scale
While deploying just two backend servers can be an effective high‑availability solution, NGINX Plus’ load‑balancing capabilities enable you to scale backend servers horizontally without the client’s knowledge.
The sample microservices environment described above is unlikely to require scaling of the backend DNS servers. However, an ISP providing DNS services to all of its subscribers experiences constant load and the potential for huge spikes, creating the need for a large number of DNS servers and a frontend proxy to load balance traffic across them.
All of the NGINX and NGINX Plus load‑balancing algorithms are available for TCP and UDP as well as HTTP:
- Round Robin (the default)
- Generic hash and its consistent variant (ketama algorithm)
- IP Hash
- Least Connections
- Least Time (NGINX Plus only)
(You can also configure weights on all algorithms to increase their efficiency even further. For a discussion, see the section about weights in Choosing an NGINX Plus Load‑Balancing Technique on our blog.)
Whereas HTTP requests can vary enormously in terms of the load and processing demands put on the backend servers, DNS requests typically all generate the same load. For this reason, the Least Connections and Least Time algorithms are unlikely to give an advantage over Round Robin. In particular, Least Connections includes in its connection count any UDP requests for which NGINX Plus is still waiting on a response from the upstream server. So long as the values for proxy_responses and proxy_timeout have not been met, NGINX Plus is still counting connections for upstream servers that may have already completed their work.
Where you have a large number of clients and a protocol that does a lot of “dialogue” – multiple messages exchanged between client and server, as in the RADIUS challenge‑response flow – then using a source‑IP hash allows that dialogue to take place with a single backend server. In other words, it establishes session persistence, meaning that NGINX Plus directs all requests from a given client to the same server. The following example configures the Hash load‑balancing algorithm for a pair of RADIUS authentication servers, with the source (client) IP address (captured by the $remote_addr variable) as the key.
upstream radius_servers {
hash $remote_addr; # Source-IP hash
server 192.168.136.201:1812;
server 192.168.136.202:1812;
}More Information
For more information about UDP and TCP load balancing, check out the following resources:
- TCP and UDP Load Balancing in the NGINX Plus Admin Guide
- NGINX Stream module and
upstreamconfiguration context - Deployment guide for load balancing Microsoft® Exchange™ servers, which must handle both TCP‑based and HTTP‑based traffic
- MySQL High‑Availability with NGINX Plus and Galera Cluster (TCP load balancing use case)
To learn about the other great features in NGINX Plus R9, see Announcing NGINX Plus R9 on our blog and watch our on‑demand webinar, What’s New in NGINX Plus R9.
To try NGINX Plus, start your free 30-day trial today or contact us to discuss your use cases.





